Hive serial (1) - Introduction to Hive
The Apache Hive™ is a warehousing infrastructure based on Apache Hadoop™, facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
Hive Concepts
Hive is a data warehouse software for data storage and processing.
What Is Hive
Hive provides the following features:
- Standard
SQLfunctionality to access to data,SQLcan be extended with user defined functions (UDFs), user defined aggregates (UDAFs), and user defined table functions (UDTFs) - Access to files stored either directly in Apache HDFS™ or Apache HBase™
- Query execution via Apache Tez™, Apache Spark™, or MapReduce
- Pluggable file formats, including (CSV/TSV) text files, Apache Parquet™, Apache ORC™ etc
What Hive Is NOT
Hive is not designed for online transaction processing (OLTP) workloads.
Hive Data Model
In the order of granularity - Hive data is organized into:
- Databases - Namespaces function to avoid naming conflicts for tables, views, partitions, columns, and so on.
- Tables - Homogeneous units of data which have the same schema, these are analogous to Tables in Relational Databases.
Tables can be filtered, projected, joined and unioned. Additionally all the data of a table is stored in a directory in HDFS. There are some types of tables in Hive:MANAGED_TABLE(default) - files, metadata and statistics are managed by internal Hive processes. Here are some features:- A managed table is stored under the
hive.metastore.warehouse.dirpath property, by default in a folder path similar to/user/hive/warehouse/databasename.db/tablename/. - DROP deletes data for managed tables while it only deletes metadata for external ones.
- A managed table is stored under the
EXTERNAL_TABLE- files can be accessed and managed by processes outside of Hive.- If the structure or partitioning of an external table is changed, an
MSCK REPAIR TABLE table_namestatement can be used to refresh metadata information.
- If the structure or partitioning of an external table is changed, an
VIRTUAL_VIEW- a purely logical object with no associated storage, created byCTASstatement.
- When a query references a view, the view’s definition is evaluated in order to produce a set of rows for further processing by the query.
- A view’s schema is frozen at the time the view is created, subsequent changes to underlying tables will not be reflected in the view’s schema.
- Views are read-only.
MATERIALIZED_VIEW- intermediate table, which stores the actual data, takes up physical space, created byCTASstatement.
- Materialized view creation statement is atomic.
- Materialized views are usable for query rewriting by the optimizer.
- Materialized views can be stored in external systems, e.g., Druid, using custom storage handlers.
- Partitions - partition columns determine how the data is stored. For example, a table T with a date partition column
dshad files with data for a particular date stored in the<table location>/ds=<date>directory in HDFS. - Buckets (or Clusters) - Data in each partition may in turn be divided into Buckets based on the hash of a column in the table. Each bucket is stored as a file in the partition directory.
Type System
Hive supports primitive and complex data types associated with the columns in the tables.
- Primitive Types
| Category | Type | Description |
|---|---|---|
| Integers | TINYINT | 1 byte integer |
| SMALLINT | 2 byte integer | |
| INT | 4 byte integer | |
| BIGINT | 8 byte integer | |
| Boolean | BOOLEAN | TRUE/FALSE |
| Floating point numbers | FLOAT | single precision |
| DOUBLE | double precision | |
| Fixed point numbers | DECIMAL | a fixed point value of user defined scale and precision |
| String types | STRING | sequence of characters in a specified character set |
| VARCHAR | sequence of characters with a maximum length | |
| CHAR | sequence of characters with a defined length | |
| Date and time types | TIMESTAMP | A date and time without a timezone ("LocalDateTime" semantics) |
| TIMESTAMP WITH LOCAL TIME ZONE | A point in time measured down to nanoseconds ("Instant" semantics) | |
| Date | a date | |
| Binary types | BINARY | a sequence of bytes |
Types can be implicitly converted in the query language.
Explicit type conversion can be done using the cast operator with the Built In Functions.
- Complex Types Complex Types can be built up from primitive types and other composite types using:
| Type | Description | Example |
|---|---|---|
| STRUCT | access element using DOT (.) | column c of type STRUCT {a INT; b INT}, accessed by the expression c.a |
| Maps | access element using ['element name'] | M['key'] |
| Arrays | access element using [n] | A[0] |
Hive Architecture
Here is the overview of Hive architecture, it consits of client, query processor, execution engines and metadata service:
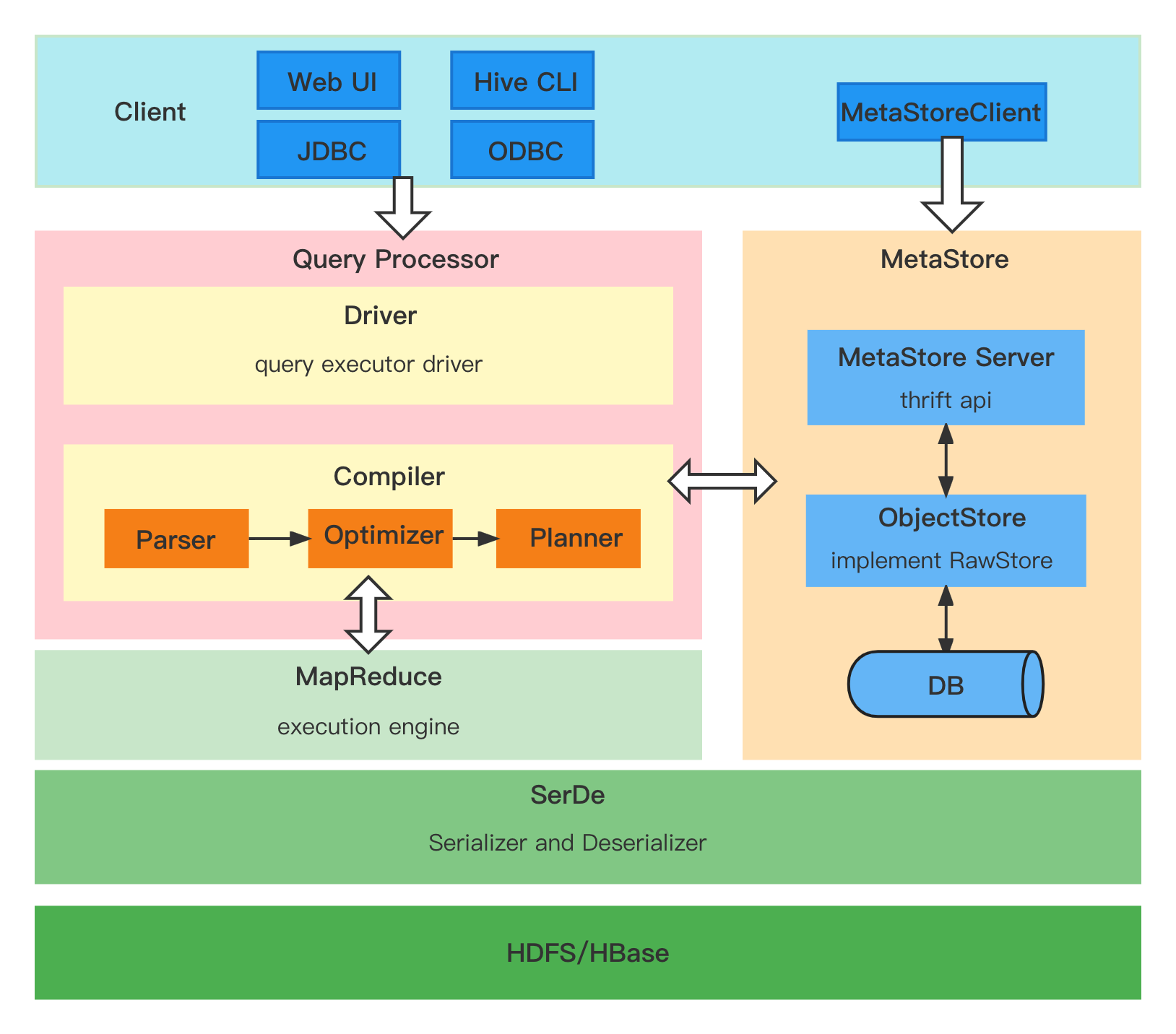
Hive has 3 major components:
- Serializers/Deserializers (trunk/serde) - contains some builtin serialization/deserialization families, also allows users to develop serializers and deserializers for their own data formats.
- MetaStore (trunk/metastore) - implements the metadata server, which is used to hold all the information about the tables and partitions that are in the warehouse.
- Query Processor (trunk/ql) - implements the processing framework for converting SQL to a graph of map/reduce jobs and the execution time framework to run those jobs in the order of dependencies.
Hive SerDe
Hive use SerDe (and FileFormat) to read and write table rows, basic work flow looks like below:
- HDFS files –> InputFileFormat –> <key, value> –> Deserializer –> Row Object
- Row Object –> Serializer –> <key, value> –> OutputFileFormat –> HDFS files
Something to note:
- the “key” part is ignored while reading, and is always a constant when writing. Basically row object is stored into the “value”.
- Hive does not own the HDFS file format. Users can access to HDFS files in the hive tables using other tools.
There are some builtin SerDe classes provided in package org.apache.hadoop.hive.serde2, like MetadataTypedColumnsetSerDe, LazySimpleSerDe et.
Hive MetaStore
MetaStore contains metadata regarding tables, partitions and databases. There are three major components in hive metastore:
- MetaStore Server - A thrift server (interface defined in
metastore/if/hive_metastore.if) that services metadata requests from clients. - ObjectStore - handles access to the actual metadata stored in the SQL store.
- MetaStore Client - Thrift clients are the main interface to manipulate and query Hive metadata for all other Hive components in many popular languages.
Hive Query Processor
Hive Query Processor handles the sql query. The following are the main components of the Hive Query Processor:
- Driver - receieves the queries, implements session handles and provides execute and fetch api.
- Compiler - parses the query, does semantic analysis, and eventually generates an execution plan with the help of table and partition metadata looked up from MetaStore.
- Execution Engine - executes the execution plan created by the compiler. The plan is a DAG of stages.
Hive Metastore Deployment
The definition of Hive objects such as databases, tables, and functions are stored in the Metastore. Hive, and other execution engines, use this data at runtime to determine how to parse, authorize, and efficiently execute user queries.
The metastore persists the object definitions to a relational database (RDBMS) via DataNucleus, a Java JDO based Object Relational Mapping (ORM) layer. There are some recommanded RDBMS for MetaStore, such as MySQL, MariaDB, Oracle et.
Deploy Mode
Beginning in Hive3.0, the Metastore is running as a standalone service without the rest of Hive being installed. Based on the backend RDBMS, there are two deploy mode for MetaStore: Embedded mode and Remote mode.
-
Embedded mode
MetaStore use embedded ApacheDerbyRDBMS, is embedded entirely in a user process. It is not intended for use beyond simple testing.
Disadvantage: Only one client can use the Metastore at any one time and any changes are not durable beyond the life of client (since it use an in memory version of Derby).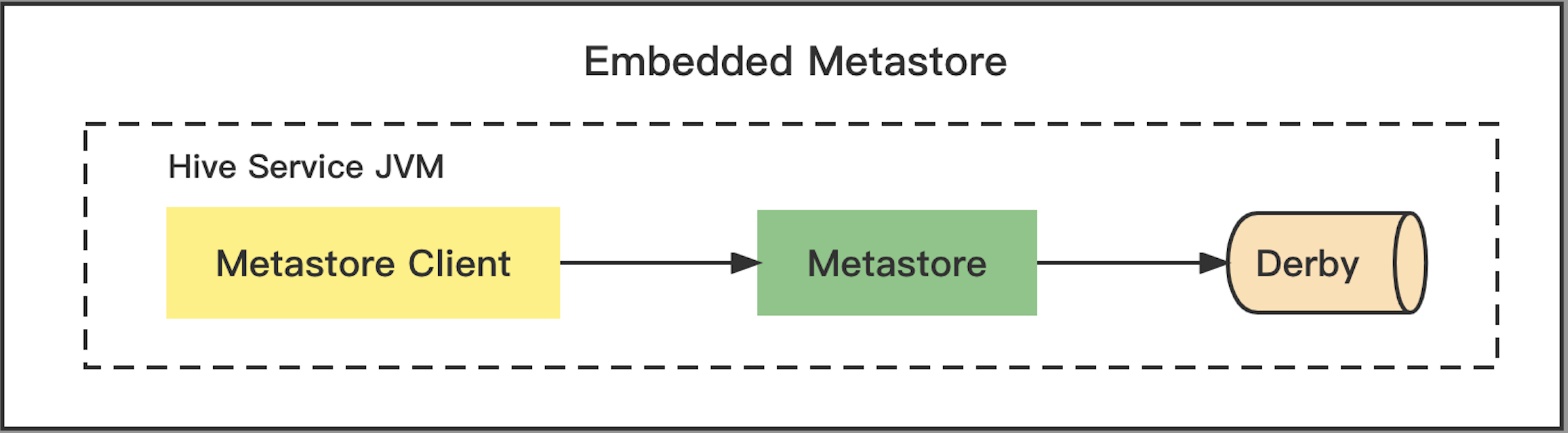
-
Remote mode
MetaStore connects to an external RDBMS via JDBC, runs as a service for other processes to connect to. Any jars required by the JDBC driver for your RDBMS should be placed inMETASTORE_HOME/libor explicitly passed on the command line.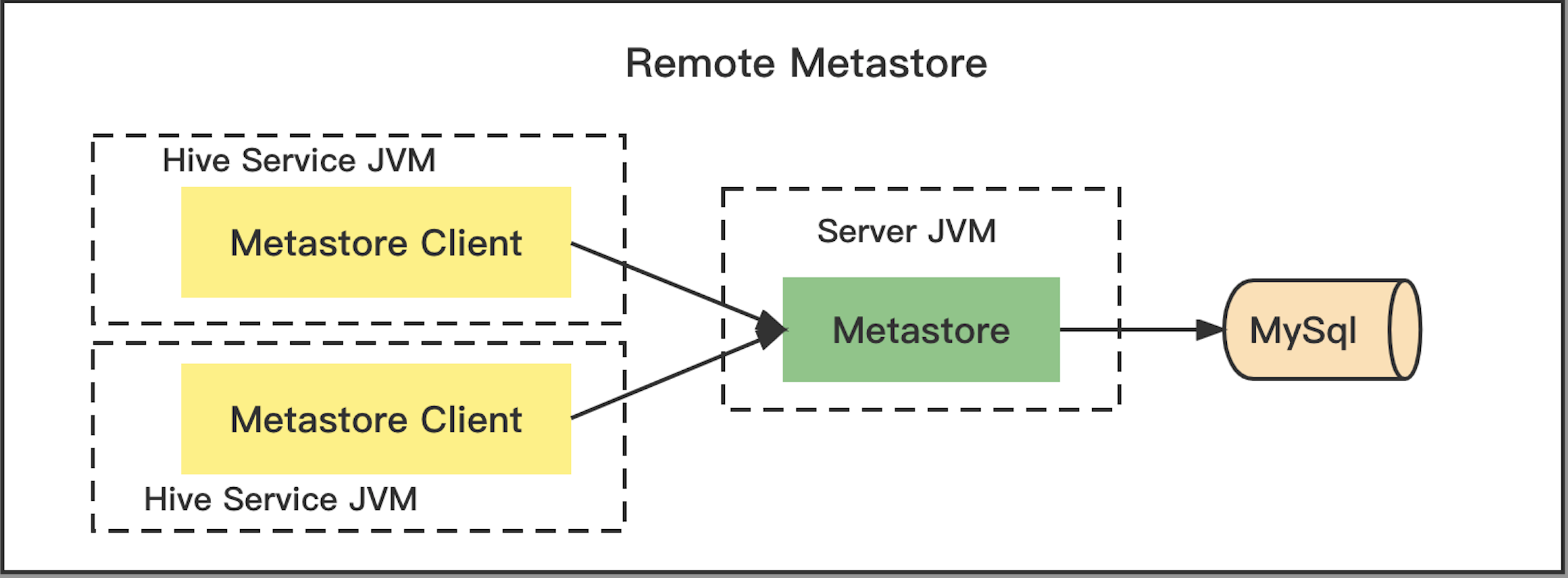
Configuration
The metastore reads all configuration files from $METASTORE_HOME/conf directory. Here are some general configurations:
| Parameter | Default Value | Description |
|---|---|---|
| metastore.warehouse.dir | URI of the default location for tables in the default catalog and database. | |
| datanucleus.schema.autoCreateAll | false | Auto creates the necessary schema in the RDBMS at startup if one does not exist. Not Recommanded in production, run schematool instead. |
| metastore.hmshandler.retry.attempts | 10 | The number of times retry a call to metastore when there is a connection error. |
| metastore.hmshandler.retry.interval | 2 sec | Time between retry attempts. |
For the Remote Metastore, you should config the following parameters for JDBC connection:
| Configuration Parameter | Comment |
|---|---|
| javax.jdo.option.ConnectionURL | Connection URL for the JDBC driver |
| javax.jdo.option.ConnectionDriverName | JDBC driver class |
| javax.jdo.option.ConnectionUserName | Username to connect to the RDBMS with |
| javax.jdo.option.ConnectionPassword | Password to connect to the RDBMS with |
There are three ways to config for the Metastore service:
- Using set command in the CLI or Beeline for setting session level values.
set hive.root.logger=DEBUG,console; - Using the –hiveconf option of the hive command (in the CLI) or beeline command for the entire session.
bin/hive --hiveconf hive.root.logger=DEBUG,console - Using config files in
$HIVE_CONF_DIRor in the classpath for setting values.- In
hive-site.xml, setting values for the entire Hive configuration.<property> <name>hive.root.logger</name> <value>DEBUG,console</value> <description>Root logger</description> </property> - In server-specific configuration files. You can set metastore-specific configuration values in
hivemetastore-site.xmland HiveServer2-specific configuration values inhiveserver2-site.xml.
- In
Deploy Practice
Using following steps to start a Hive Metastore service.
1. Requirements
- Java
- Hadoop 2.x (preferred), 1.x (not surpported by Hive 2.0.0 onward).
- Hive is commonly used in production Linux and Windows environment. Mac is a commonly used development environment.
2. Get Hive tarball and unpack
There are two methods to get the hive tarball:
- Download from hive stable release.
- Compile from resources:
# hive 1.0 mvn clean package -DskipTest -Phadoop-1,dist # hive 2.0 and onward mvn clean package -DskipTest -Pdist
Unpack hive tar ball and set HIVE_HOME and HIVE_CONF_DIR (optional):
tar zxf hive-x.y.z.tar.gz
export HIVE_HOME=/path/to/hive
export PATH=$HIVE_HOME/bin:$PATH
3. Start metastore service
Hive uses hadoop, so must have hadoop in your path:
export HADOOP_HOME=<hadoop-install-dir>
export HADOOP_CONF_DIR=<hadoop-conf-dir>
In addition, you must use below HDFS commands to create /tmp and /user/hive/warehouse (aka hive.metastore.warehouse.dir) and set them chmod g+w before you can create a table in Hive.
$HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
Init database schema if you start metastore service for the first time:
$HIVE_HOME/bin/schematool -initSchema -dbType mysql
Then start hive metastore service:
nohup $HIVE_HOME/bin/hive --service metastore --hiveconf hive.log.file=hivemetastore.log --hiveconf hive.log.dir=/var/log/hive > /var/log/hive/hive.out 2> /var/log/hive/hive.err &
4. Smoke test hive
- Open hive command line shell:
$HIVE_HOME/bin/hive [--hiveconf hive.metastore.uris=thrift://<host>:<port>] - Run sample commands:
show databases;create table test(col1 int, col2 string); show tables;
For convenience, we provide a docker tool to start a tiny hive metastore service, please refer to hadoop-docker.